Challenge
Conjur is built to allow you to control access to your critical systems. This makes Conjur a critical security service. Given its role, here are some of the stringent requirements that the Conjur service must satisfy:
- Authentication of existent and new workloads in dynamic systems such as Kubernetes, on every request
- Application of permission checks (authorization) and auditing on every request
- Low latency
- Cannot stop serving secrets
- High elasticity to accommodate varying levels of traffic
- Deployment in a variety of environments: on-premise, different clouds, within orchestrators, etc.
In a word, the Conjur service must be infinitely-available.
Approach
In designing the high availability architecture for the Conjur Service, we exploited the fact that almost all traffic to the Conjur service is for read operations. Read operations include secret retrieval; authentication, which we designed to use cryptography (signed tokens, certificates, etc); and authorization. In this way, Conjur can serve the needs of workloads without needing a writeable data store. This allows us to promptly discard architectures constrained by write characteristics and focus on read scale.
Attention quickly moves to the source of truth, the database. An architecture with the database as a separate tier is not viable as it pushes traffic to that layer and creates a read bottleneck. It also introduces latency if the database is running on a different machine. We address these issues by opting for a shared-nothing 12-factor architecture that incorporates the DB within the Conjur appliance. In this architecture there is a distinction between nodes based on how their databases are populated. A single master node exists whose responsibilities are scoped to handling writes and replication requests. Follower nodes are read replicas of the master node. All traffic within the cluster is secured by verified TLS.
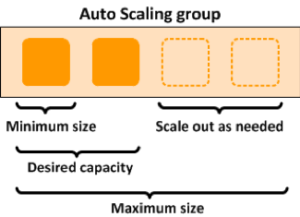
The Conjur follower node is an ideal unit of scaling. Followers are cheap and interchangeable, in tune with the principle of immutable infrastructure. The number of followers you have corresponds to your scale for read operations. This architecture maps beautifully to Auto Scaling Groups, meaning you can set up your Conjur cluster to provision new nodes in response to traffic. The same principle applies to running Conjur in orchestrators such as Kubernetes.
Redundancy, however, is not a sufficient condition to provide high availability. If anything, redundancy ought to be opaque to the services that consume the underlying resource. In practice, there exists a load balancer on top of your Conjur cluster that uses the Conjur built-in health check to route traffic to healthy followers. When a follower becomes unavailable, the load balancer will stop redirecting requests for that specific follower. In a similar vein, we recommend that followers connect to the master through a load balancer to avoid the need for reconfiguration in the event of failover – the Conjur High Availability architecture addresses the risk of master failure with standby nodes, able to assume the role of active master in the event of master failure.
Result
Conjur elegantly satisfies the requirements of a critical security service through a shared-nothing high availability architecture based on read-only followers. Each follower using the database next to it can apply authentication, authorization and audit every request, and it can do so with minimal latency. The cluster need never stop serving secrets because it has the capability to scale in response to surges in traffic. Given a link to an active master node, followers can be deployed in a variety of environments close to the systems that they serve.
Don’t take my word for it, you can put this architecture to the test for yourself! Observe how followers get spun up like clockwork by the Auto Scaling Group. Drop a master and observe how auto-failover handles the loss with zero uptime effect on secret retrievals. It all just works.

Kumbirai Tanekha is a Software Engineer in the R&D department at CyberArk. He has a keen interest in developing intelligent tools to streamline and facilitate workflows. He enjoys using and contributing to OSS software, and strives to be an effective communicator of complex ideas.